 |
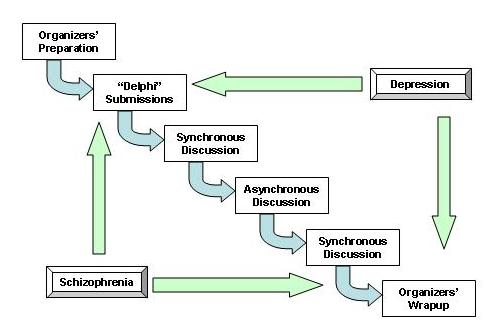
Figure 1. Overview of the web conference process
| Project Metadata | Keywords | |||||||||||||||||||||||||||||||||||||||||
|
|
In 1997 the International Psychopharmacology Algorithm Project (IPAP) experimented with a web-based conference to create two algorithms for the treatment of psychiatric disorders, hoping to speed up the process of creating algorithms. As with earlier algorithms, these were "consensus" based algorithms, rather than "evidence" based. That is, the algorithms were derived from the clinical and research expertise of the authors, with citations to the evidence, rather than being derived from the research evidence, with additions based on the authors' expertise.
A group of experts in several fields (e.g., informatics, information science, library science, and operations research/modeling) observed the preparation and conduct of the IPAP web-based conference and analyzed what they saw and heard. The novel format of the conference introduced several possible benefits, such as reducing the total participant time required, reducing the total cost of the conference, increasing the level of evidence-based reasoning, and permitting extended conferences. On the other hand, it was not clear whether the format might introduce additional problems that would degrade the quality of the output algorithms. The observers concluded that many (though not all) of the benefits were achieved and that, while there were some problems with the format, the algorithm quality did not appear to be degraded. These results were reported in the literature (see 1998, Publications - External Review).
The lessons from this conference influenced later IPAP efforts, both publications and the production of evidence based algorithms.
Figure 1 shows the broad structure of the conference, in which algorithms were created for depression and schizophrenia. The conference organizers created the working environment, elicited initial algorithms for each disease, coordinated the synchronous web-based teleconferences, and coordinated the reporting of the conference's results (this set of articles). The novel format of the conference introduced several possible benefits, such as reducing the total participant time required, reducing the total cost of the conference, increasing the level of evidence-based reasoning, and permitting extended conferences. On the other hand, it was not clear whether the format might introduce additional problems that would degrade the quality of the output algorithms. The organizers decided to include an observer panel within the conference structure to listen to the discussions involved in creating the algorithms, observe the conference support structure in action, and comment on significant points. The differing viewpoints were sought as means of ensuring that no significant points were missed.
|
Figure 1. Overview of the web conference process
The panel of observers included professionals in several disciplines:
Figure 2 illustrates the planned process for the synchronous sessions. The participants were envisioned as viewing the algorithms on their computers, discussing them over the telephone conference, producing updated algorithm versions, and consulting the reference databases. The two algorithms are shown in Figure 3 and Figure 4. The observed personal interactions, decisions, leadership, and update timings are described in this section.
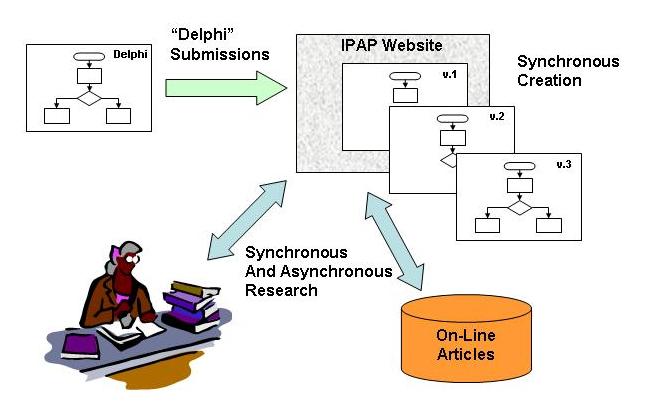 |
Figure 2. Details of the web conference process
Both sets of group members were extremely polite in not talking over each other; however, the schizophrenia group had a livelier conversation style and had the only collision of speakers (multiple speakers trying to advance an argument at same time). Both groups were quick to learn voice name relationships and appeared unaware that they are not face to face in their interactions. However, it was hard (for the observers) to tell if everyone was participating.
In the first session, there was an initial discussion on the completeness of the working algorithm definition (i.e., what diagnosis should it cover). This was followed by considerable discussion on the proper principal "cut points" to divide patients and thus the algorithm. Other shaping discussions included whether the prescription should be a class of drugs or an individual drug, that they should consider safety, history, broadness of effectiveness of drugs, but should not put these in algorithm. There was discussion of the identity of the algorithm user and the impact this question has on the algorithm. There was some discussion of evidence and economics.
In the second session, the discussion included points about the algorithm itself, but also covered scientific and philosophic points. For example, it was pointed out that evidence from inpatient studies is not clearly transferable to outpatients. The comment was made that there is evidence for various treatments, but that it was not clear that this is reflected in actual practice. There was discussion about structure of the algorithm and meaning: should severity be attached to the individual decision boxes or should there be separate severe and non severe algorithms. There was more discussion about lower (later) level of the algorithm and discussions on several details, such as extra symptoms besides depression; medical problems, psychosocial stressors, personality problems; misdiagnosis, the need to review diagnosis because things have changed, etc.; and the value of family history or past history of drug response.
The planned discussion on the tactics of maximizing response to a particular drug had been put off until the second session, but was not covered. The group did not get to defining terms, giving evidence for decisions, or giving probabilities of success. Initially, it appeared that the algorithm was going to be excessively general, allowing almost all treatments at all levels. Even at the end, the boxes were very dense with optional treatments, a potentially confusing situation. Further, the definitions of several terms were assumed: severe, complicated, response, atypical, significant. There was a clear need for a third session.
The third session (conducted solely as a conference call) cleared up the end of the algorithm. Individual participants agreed to address some of the problems of definition, evidence and probabilities of success.
|
|
Figure 3. Flowchart for the 1998 IPAP Major Depression consensus algorithm
In the first session, a discussion of side effects (risks) and economics occurred early. There was more discussion of economics than in depression group. The schizophrenia group spent more time on technical points and less on philosophical points. This group was more concerned with what dosage and drugs are legally approved than was the depression group. There were discussions of complications, of response vs patient preference for a given drug, of whether side effects means immediate tolerability or long term problems, and that compliance is an issue that must be addressed in schizophrenia. There were some discussions on philosophical points, such as a discussion on how drugs should be classed (e.g., are all atypicals alike) and a request of the organizer about the nature of the algorithm. However, there was more expectation of having to try many approaches (e.g., some people do well on one drug or another for no known reason) and less conviction in the answers than in the depression group. Toward the end of the session the organizer requested a discussion on levels of evidence and probabilities of response, which did lead to some discussion of levels of evidence.
The second session was principally a philosophical
discussion of the algorithm structure and its meaning as a whole. There was
a general feeling that the algorithm was complete.
|
|
Figure 4. Flowchart for the 1998 IPAP Schizophrenia consensus algorithm
The leader of the depression group used directive leadership, for example, he declared "strategy" meant to decide on the steps and "tactics" meant how to maximize a drug's effects and scheduled the sequence of discussion. He did a good job of leading conversation and of developing consensus. At least four of the members had considerable prior experience in developing algorithms. On the other hand, the leader of the schizophrenia group used a consultative leadership style, inviting comments from specific people. He was very good about asking clearly about consensus; however, when he asked for volunteers to address levels of evidence, prob of response, etc., to finalize the algorithm, there were no ready responses. Both leadership styles worked well.
The schizophrenia group appeared to have a more cookbook approach, including dosages in the algorithm, while the depression group never mentioned dosage (perhaps an artifact of the starting point algorithm). The drugs used in schizophrenia may be more dangerous and there are new drug classes; the problem may be harder. The fact that depression appears to have a better theory of the mind and drug actions may have influenced the discussion. It may also be germane that the depression group had a majority of members with considerable experience in creating algorithms. The schizophrenia group had more regular algorithm updates and had more discussion of economics. The depression group felt a need for more discussion and added a third session.
Table 1 show the timings during the sessions for each of the groups. The depression group made few changes to the algorithm in the first session; whereas the schizophrenia group made several changes in regular progression. The depression group added a third session, which brought the number of their changes up to a comparable level with the schizophrenia group.
Table 1. Algorithm Revisions
| Depression time of revisions |
Schizophrenia time of revision |
|
| Session 1 | 00 - initial 30 60 90 |
00 - initial 14 35 51 63 83 |
| Session 2 | 00 - cleaned up version 40 67 |
00 - cleaned up version 40 55 - final version |
| Session 3 | 00 - cleaned up version 60 - final version |
The systems used to support the conference consisted of a multiparty telephone call; a world wide web display of the algorithms, with updates being posted to new pages; and reference access through OVID and the National Library of Medicine (NLM) PUBMED automated reference support. The observers were supported by a chat room to avoid intruding on the conference discussions, either listening to the discussion over the telephone or using RealAudio (RA), and watching the algorithm changes on the web.
Extensive preparation was required. The many experiments, trials and test meetings proved their value (see Table 2). The tests demonstrated that creation of a 'state of the art' system would have resulted in failure. The system that was chosen used less elegant, but more robust elements, and was successful.
Table 2. System Trials
| Website | Installed at Stanford: no problems |
| Mail lists | Installed at Stanford: no problems |
| Audio | Audionet: Audionet had feedback with too many participants Plain Old Telephone System (POTS): POTS worked well, easily set up and used RealAudio (RA): RA worked well for listening only and for recording |
| Visual | Java whiteboard: failed in complete connectivity Farallon Look@Me: several trials, too complicated Farallon Timbuktu: delays, too complicated PictureTalk: failed, slow, unreliable, expensive MacFlow with .gif file posting, viewing using browser: clear, worked well |
| Chat | first chat: cumbersome to enter text, but had time stamping Biapchat: somewhat better, but had no time stamping |
| OVID connection | Installed at Stanford website: no problems |
| PubMed connection | Installed at Stanford website: no problems |
Several lessons were learned from this experience. The following list relate to the organizers' issues.
Participant responsibilities include the following:
POTS worked well; however, recognizing voices has a learning curve. At the beginning of each session, each participant should identify himself so it's easier to match voices with names. If all the participants know each other, this is less significant, except for observers. Chairs need to remember to draw out those who are not saying much to aid in consensus building. A formal "roll call" on important consensus points is helpful, not only to get a vote tally but also to stimulate comments from the more shy participants. Unfortunately, POTS does not provide eye contact as an aid for getting volunteers.
Posting the algorithms as updated worked well, looked good and was quite useful. It was superior to faxing the updates. Having previous versions, including pre conference submissions, to look at was valuable. The MacFlow software worked well and generated very clear .gif files for display on the web. Alternative "whiteboard" software would have permitted group mark up (of questionable desirability), but would never have permitted clear, complex flowcharts. A "pointing" facility for the participants would be a useful addition. This is possible with some groupware (e.g. Farallon Timbuktu), but as we learned these were not reliable enough or simple enough to install to permit group use (at least not without proper local technical support). It might be useful to have a chat window in the algorithm box for participants to insert comments and post references.
Possible improvements to the algorithm presentations include: flow charts with HTML or AcrobatTM hypertext links (getting everything on one physical page is difficult); labeling action nodes to indicate that there is some uncertainty; using box frames, bold fonts, different typefaces and font sizes, or colors to indicate level of agreement, level of evidence, etc.; or possibly using Java to open a small text box with notes on evidence and/or certainty level at appropriate nodes.
Digitized pictures of the participants would add to this, esp if they could indicate who was speaking. (Live "talking head" video displays are possible, using CU See Me or similar software.) This would involve a webcam, some bandwidth, and most crucially local or IPAP technical support to install it. At the very least, still photos of the participants would be a useful psychological aid in knowing who's speaking.
At times the person doing the online updating of algorithms had some difficulty both following the conference and doing the mechanics of updating. It might help to have two people at the same location doing the updating. One could be listening more closely and taking notes. The other could be listening and wrestling with the mechanics.
Most office computers are set in a desk corner or for the convenience of the single user and are not well situated for shared listening and screen viewing. If a conference involves more participants, they may need to consider alternative shared viewing areas, i.e., using computer facilities other than a personal office.
Despite the appearance that the reference resources were unused, the facility for full-text retrieval through OVID did sustain some use. OVID reported use from 79 different IP addresses used 11 different databases, with an average connect time of 23 minutes. (An IP address denotes either a unique computer for hard-wired Internet connections or a unique log-on occurrence for dial-up Internet connections.)
Besides the standard problem of learning how to use the chat software, there were some technical problems with this particular software: the window size was too small and could not be resized; text did not 'flow' to a new line; and time stamping of chat contents was not included. In practice, it periodically lost all records on screen; connection was lost if the user resized the browser window or switched between web pages (a separate browser window should be used for the chat function); and the connection popped in and out during the second sessions. Some observers found it difficult to listen to the conference and read several threads of conversation at the same time. However, the chat was useful for seeing who was on line at any given time; passing instructions, comments and questions for the observers only; and keeping a record of the conference events.
The RA product was a mixed success. It did provide a permanent record of the discussions for later analysis; it provided the ability to check on who was using RA; and, for those observers who could use it, it provided the sound of the conference while avoiding distracting the participants. It also provided the audio without requiring holding a handset to the ear for the entire conference. However, it did not always work; it was not clear when it was supposed to be working; the automatic install was not always complete (install failed when another process had captured the audio); there was a delay in RA compared to telephone 5-10 seconds; one could occasionally hear RA over the telephone; and it was not working at all for one session. The sound quality was excellent at Stanford; however, the quality elsewhere varied, depending on CPU speed, RAM available and speaker quality.
Some of the problems would have been resolved by more testing. Each user must test his or her own system reception with the RA home page site after installing. In addition, there should be a sample audio file on the IPAP site to test the RA feed. Given the problems (some inherent) with RA, future sessions might consider total POTS audio. Some conference call systems allow both "active" (speaking and listening) and "passive" (listening only) participation. Even with this choice, RA could provide recordings of the sessions for future broadcast or analysis.
Standard conferences require both technological systems (e.g., audiovisual equipment) and some organizational systems (e.g., meeting structure and internal session structure), with an emphasis on organizational systems. This conference also required both technological and organizational systems and while there was more emphasis on the technological systems, the organizational systems also required attention.
Unlike a conventional conference in which the organizers disappear once the meeting starts, in this type conference, the organizers are vital to the conduct of the meeting. The chief organizer is required as final arbiter. The keeper and creator of the physical algorithm must be knowledgeable about the medical issues under discussion, as well as the algorithm drawing program. An experienced webmaster is required to ensure that technical problems are dealt with quickly. Finally, as always, choosing knowledgeable people with good group leadership skills to chair each working group leads to good meetings.
The structure was defined as: a pre-conference work up of an algorithm starting point, a synchronous discussion session, an asynchronous collaboration and research opportunity, a synchronous discussion session, and off-line report generation. The pre-conference work up could use improvement. The synchronous discussion sessions worked well; however, one group added a third synchronous discussion session (POTS only). One of the biggest difficulties with an online conference is the lack of opportunity to continue discussions during breaks and over meals; there's no opportunity for spontaneity. Also, it is not clear how much research or collaboration took place between the synchronous discussions.
Having a starting algorithm appeared to be good plan; however, obtaining that starting point posed some problems. Several depression algorithms were submitted, from which a merged baseline algorithm was to be created. The influence of the South African algorithm led to some queries, as not all the drugs mentioned are available in the U.S. On the schizophrenia side, the initial algorithm specified dosages, perhaps leading to a more "cookbook" algorithm and discussion.
A suggestion to improve the pre-conference work up is the "admission ticket" concept, which would require each IPAP session participant to submit an algorithm in advance, coupled with supporting references. Before the synchronous sessions there would be a database of supporting references (on the website) and the Delphi submissions would indicate the level of evidence for each proposition. Final versions of the algorithms would have hyperlinks to the supporting evidence (presumably as Medline references).
It also seemed that the two sessions were not enough, and the second session was too short. Scheduling more sessions would probably be more effective than increasing their length. Three to four sessions might be scheduled; if a group didn't need the time, they could cancel the additional sessions. Considering how busy all the participants are, it's probably easier for them to pre-schedule several sessions than to run out of time and have to agree on an unanticipated session.
It is clear that the attempts at providing online research assistance worked poorly. It was assumed that the (free) OVID and PubMed use would precede the conference sessions or occur during the asynchronous interim period. Some use of OVID did occur, but its value was unknown. In addition, the NLM reported that there were no requests for librarian assistance during the conference.
The sessions need better defined agendas. A formal statement at the beginning of each working group as to what kind of algorithm should be created was needed. (This would include a formal declaration of who users should be: clinicians, some internists, family practitioners, nurses, etc.) Formal definitions of terms such as, severe, complicated, response, atypical, significant, and side effects, were needed.
There was a need for a more formal process for ranking the importance of areas of disagreement, deciding which could be resolved in real time, and which needed to be resolved by gathering more data and possibly taking a vote. A web based voting system (with anonymous voting or participant identification) might be possible.
The politeness of the participants in avoiding overriding other speakers was noted. Apparently this is common in phone conferences. However, it is debatable whether this is a good thing. Certainly, extremely heated discussions with no agreement would not result in an algorithm. However, there is a possibility that some heat may be good. Consider "compromise" versus "synthesis." A compromise may be arrived at by disengaged participants who do not feel compelled to support the result at a later time. A synthesis might require enough heat to "melt" the hardened stances of participants holding opposing positions, engendering lasting support. Excess heat might yield agreement through brow beating, with later disavowal of results. The problem is in determining whether compromise or synthesis was achieved.
One feature that was proposed as an improvement over standard conferences was the provision of access to the literature. Unfortunately, this feature did not appear to be heavily used. The apparent indifference to the online links to the literature may have resulted from adequate support from the participants' own libraries.
In the schizophrenia group, there were occasional questions about dosages or specific papers that could have been answered by a reference librarian, but no one referred questions to the NLM. However, there is a difference between thinking out loud in a group, wondering what a dose range might be, and taking the step of asking someone to find out. The participants may have felt that when it came time to put pen to paper, they could verify these facts themselves.
It would be very difficult to do any kind of research while the sessions are ongoing. As soon as a listener goes off to track down a fact, that person is no longer available to listen and identify additional questions. The obvious solution is to listen, take notes, and pursue research after a session. The librarian listener would need to confirm with the session chair (after the session) that information was really needed, because many questions that might arise in discussion may, upon reflection, not warrant further research. For any research, a modern librarian relies heavily on computer access. With two Netscape sessions open, one for the chat room, one to view the algorithms, and a RealAudio session open, trying to then also search MEDLINE could overwhelm both the computer and the librarian-listener's own faculties. (Assuming that the computer used to listen to the conference was connected to the library's collection.)
For each NIH Consensus Development Conference, the Reference Section staff at the National Library of Medicine puts together in depth bibliographies of citations and abstracts from MEDLINE and other relevant databases. The assigned librarian consults with a subject expert to define the scope of the bibliography. These are distributed to panel members (those who actually write the consensus) several weeks before a conference. Other conference participants receive a printed bibliography of citations (no abstracts) at the conference. The bibliographies are also available on the Internet. These bibliographies give consensus panelists a chance to review the literature prior to meeting.
For conferences such as IPAP, any of the participants working with his or her institution's library staff could compile the same type of bibliography ahead of time, sharing it by mail, fax, or posting on the Internet. When the NLM prepares a bibliography, they do considerable editing of citations for consistency, divide citations by subject, write prefatory material, etc. because their bibliographies are formal products. For a conference such as this, it would be sufficient to skip all these steps, print the retrieval as the vendor provides it and share the results among participants. The emphasis would be entirely on content, not the polish of the finished bibliography. A pre-conference bibliography would also confirm what the schizophrenia group often mentioned that the literature was scarce on some drugs and the evidence mostly based on clinical experience.
Although evidence and probability of response questions were specifically raised prior to the conference (by email broadcast and during audioconference), they were not well addressed.
It is important to address the question of doing "evidence based" medicine in the absence of good evidence. The assumption of the field of evidence based medicine is that physicians will practice better medicine if they get into the habit of referring to the research literature and doing simple analysis of the statistics reported in clinical trials before making treatment decisions. The field of evidence based medicine offers ideas about labeling bits of knowledge by their source (i.e., clinical trials vs case control studies vs anecdotal experience). However, the field does not offer much help in how to incorporate the anecdotal experience of others into the decision making process.
The conference group pretty much agreed on treatment steps in areas of psychopharmacology where some clinical trials exist. The questions which resulted in the longest discussions and the most difficulty in reaching consensus were those in which no clinical trials existed. "Evidence based" medicine will not help in cleaning up these parts of the algorithms because there is either no evidence with which to work, or the small amounts of available evidence conflict with each other.
Clinical algorithms are a type of knowledge based system. In order to create a knowledge based system whose performance on different clinical problems is consistent, the system designer needs either [1] a reliable source of published knowledge on which to base the system, or [2] a single decision maker who can be considered an expert, whose knowledge will be modeled through extensive interviewing sessions (knowledge acquisition). The second approach can capture unpublished decision making expertise that some expert has gained over many years. It presumes that some acknowledged expert in the field can be found, i.e., someone who is felt to make correct decisions most of the time on the issues in question. The final system will incorporate both the expertise and any biases of the expert.
In a field such as psychopharmacology in which the knowledge changes very fast, there is both a lack of research evidence on the more problematic questions and no single expert who has run through enough cases to feel a high level of confidence in making statements about the "correct" steps to take for the more complex clinical problems.
In the conference group the contributors all agreed that they did not feel that they were experts when it came to the decision points that would be most difficult for the practicing psychiatrist. An approach to formalizing knowledge on these issues somewhat might be to go through a more formal application of traditional consensus methods, such as the Delphi process; that is, making a clear statement of the issue under consideration, taking a vote on the decision alternatives, and recording the results of the vote. This at least might offer a more formal description of the degree of uncertainty in the group about the appropriateness of a proposed algorithm step. This conference uncovered a new use for algorithms: let users know when they have entered terra incognita.
A separate session devoted to these issues would probably be best. Two sessions to derive the treatment algorithm would then be followed by an attempt to ascribe the response/evidence level to each step. (Note that clinicians will sometimes want to/need to prescribe something that has worked for them "anecdotally" or without A Level evidence; that's why the treatment flow should be determined first.)
The novel format of the conference succeeded in reducing the total participant time required. It also reduced the costs to the participants of the conference; however, the analysis of total costs (considering one-time and recurring costs for similar conferences) is not yet complete. The conference did not succeed in increasing the level of evidence-based reasoning. It did, however, permit extending the conference (by adding an extra session), which would have been extremely difficult in a conventional conference.
The format did not introduce additional problems sufficient to degrade the quality of the output algorithms. The decision process of the conference appeared to flow as well as at conventional conferences. Presumably, the algorithms that were produced were not inferior to those that would have been produced in a conventional conference.
However, a separate issue is the "value" of an electronic conference to participants, i.e. in gaining academic promotions or funding. Currently, the value attached to this format may not be the same as a formal, established, physical conference on a curriculum vita. Further, the advantages of a phone and web based teleconference (reduced time away from work and convenience of location) are also potential disadvantages. A web-based conference may not achieve the same level of internal "priority" as a physical conference with plane reservations and conference halls. The issue of personal value may not have had a great impact on this conference because of its experimental nature; however, it might be important in any subsequent conferences.
One final observation of the non-physician observer group concerning the overall process deserves airing. Algorithms have been criticized as leading to "cookbook medicine;" however, the pejorative sense of the phrase may need some rethinking. Excellent psychiatric treatment is an art and great cooking is an art. Cookbooks are not all bad; they let the rest of us approach good cooking. How do we capture the beneficial connotations of the cookbook in designing and depicting an algorithm?
The observers concluded that many (though not all) of the benefits were achieved and that, while there were some problems with the format, the algorithm quality did not appear to be degraded. The observes rated the conference as a success.
If you arrived here using a keyword shortcut, you may use your browser's "back" key to return to the keyword distribution page.
![]() Return to
Hartley's Projects Page
Return to
Hartley's Projects Page